The diameter of a binary tree is the longest path between any 2 nodes in the tree. The longest path here refers to the number of edges between the 2 nodes. The 2 nodes may or may not constitute the root node of the tree, the only constraint being that the path between should has to be the longest.
Example:
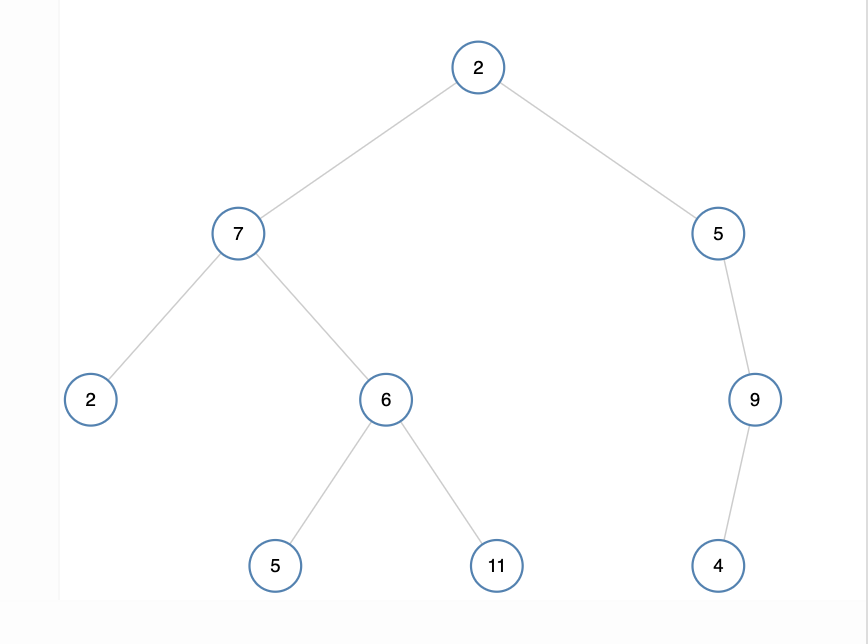
The longest path here would be from 5(leaf) to 4 [5->6->->7->2->5->9->4] or it could be 11 to 4. Both paths have a diameter of 6.
Approach to solve the problem
To find out the diameter of a binary tree, a naive approach could be picking up any 2 nodes at a time, and finding the path length between them. The time complexity for this would be: [assuming n nodes in total]
Firstly, we would need to find a path from the root to each of the chosen nodes. Complexity to find the first node: logn (max height of the tree). Complexity to find second node: logn (max height of the tree)
If we are picking 2 random nodes at a time, total such combinations = nC2. Total time complexity = nC2 * 2logn = n2logn
Clearly, this time complexity would be unacceptable, if the question is asked in an interview.
A better complexity solution
Can we make the above time better? If you think of it, the above question can be broken into parts.
Diameter at the root can be:
Paths between chosen 2 nodes, which includes the root
———————————–OR———————————————
Max of (Diameter from left subtree of the root, Diameter from right subtree of the root) [not including the root in this case]
Example
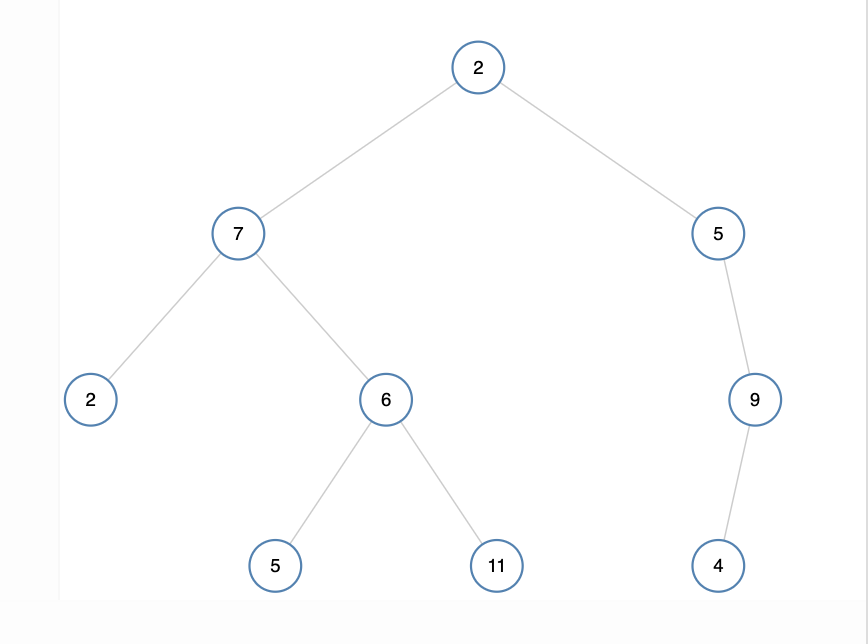
Diameter = 6 [includes root]
Another Example

Here the diameter comes from the left subtree of the root and it would be 7. [Path between 8 to 10]
We don’t know what the chosen 2 nodes are, but we are concerned with the diameter. So, using the above analysis, it’s easy to translate this to a recursive solution, wherein, at each level
- Either the subtrees would provide the diameter.
- Subtree would pass the length of longest path from subtree root to leaf to the previous recursive call [Eg in this case, subtree at 2 would pass 4 (length between 2 and 10) to the previous recursive call to 1.]
This was just to provide an overview of the solution we would be working on. The agenda of the post is an iterative solution, which works in a similar way.
The only challenge iterative approach poses is how would you pass the results of subtree [longest path length from subtree root to leaf] to the level above it. Since there’s no function call return mechanism like in recursion, we would need to keep some kind of storage for this. In a brief, here are the steps:
- Maintain 2 storage structures:
[Stack -> to replicate recursive behavior. Each node would be part of the stack 2 times. The first time, we would pop it, and check whether we have processed its children, if no, we would push it again.
The second time, we would pop it, and the children would have been processed by this time, so we would just update the longest path length that the subtree rooted at this node provides]. - Loop in while the stack is not empty.
- Return the value from the max variable.
The steps above just give an idea, here’s the code:
Code snippet
public class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode() {}
TreeNode(int val) { this.val = val; }
TreeNode(int val, TreeNode left, TreeNode right) {
this.val = val;
this.left = left;
this.right = right;
}
}
class Solution {
int max = Integer.MIN_VALUE; // This will store the diameter.
public int diameterOfBinaryTree(TreeNode root) {
// Base case.
if (root == null || (root.left == null && root.right == null)) {
return 0;
}
HashMap<TreeNode, Integer> map = new HashMap<>();
// Instead of node.val we’re storing node, as there can be multiple nodes with same values.
Stack<TreeNode> stack = new Stack<>();
map.put(root, 0);// Root’s children aren’t processed, so set value to 0.
stack.push(root);
while(!stack.isEmpty()) {
TreeNode node = stack.pop();
if (map.get(node) != null && map.get(node) == 0) {
map.put(node, 1);// This is to indicate we will now process children for this node
stack.push(node);
if (node.left != null) {
stack.push(node.left);
map.put(node.left, 0);
}
if (node.right != null) {
stack.push(node.right);
map.put(node.right, 0);
}
} else {
// We enter here when we know both children of the popped node have been processed already.
int lMax = node.left == null ? 0 : map.get(node.left);// Get longest path from left subtree.
int rMax = node.right == null ? 0 : map.get(node.right);
updateMax(1 + lMax + rMax);// This updates the max variable in case present value is greater. This indicates the path length which includes the popped node.
map.put(node, Math.max(lMax, rMax) + 1);// Update popped node value in map so that it’s parent can use it.
}
}
return this.max - 1;// Subtract 1 since we need edge count, but we stored node count.
}
// Self explanatory, just updates max if value is greater than max.
private void updateMax(int value) {
if (this.max < value) {
this.max = value;
}
}
}
Time complexity : 2*O(n) -> since we are touching each node twice = O(n).
Space complexity : 2*O(n) [for map and stack] = O(n)
For more posts on Data Structures & Algorithms on Tech-Guidance click here.